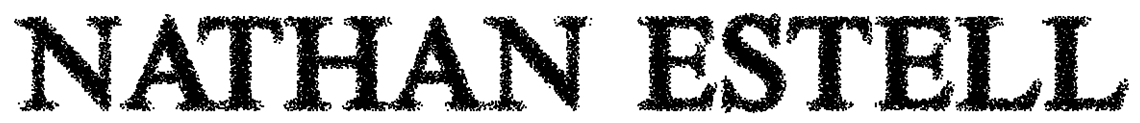
This is a clever PowerShell one liner that I saw on a forum. To start breaking this down, we’ll look at the middle part since that’s what runs first.
This just creates an array of numbers from 0 to 12. Each one of these numbers is piped (“|”) to the “%” which is an alias for the ForEach-Object cmdlet. This does everything in {} on each of those 13 numbers. What’s inside there?
As you might guess, the name is encoded in the large number in the middle. Each letter is in the form of ASCII character codes. This number is in the form of a string because of the quotes around it.
The substring function runs on this string. The first parameter is what position it should start at, and the second parameter is how many characters to go. The “$_” stands for the current number that is being worked with. It will be the numbers 0-12 that came into the ForEach-Object cmdlet. For the first number, which is zero, the substring will start at position 0 and will end at position 2. Here’s an example of substring:
As the numbers being input go from 0 to 12, the section of the string being selected will move to the right. The first section will be “46”, the second will be “65”, and the last will be “76”. To each of these sections is added an offset of 32. Why isn’t the 32 just added into the original big string? Then the original string would be “7897116104971103269115116101108108”. This causes problems because now some of the sections are 2 characters in length like before and some are 3 characters long. The substring would not be able to get the section correctly by using 2 as its second parameter.
Because the letters go from ASCII #65 to ASCII #122, you can use any offset between 23 and 65. If the offset was 23, the largest ASCII number when represented in the string would be just under 3 digits and would be 99. If the offset was 65, the smallest ASCII number when represented in the string would just avoid a negative sign and would equal 0.
With the 32 added, we have the ASCII code in integer form. To convert it to the character we use [char]. This acts on what’s in the parentheses after it. When all the numbers have been processed there is an array of characters:
To get this into a string, we use [string]. This acts on what’s in the parentheses after it.
Notice that there are now 3 spaces in between the first and last names instead of 1. I think this is a bug in the [string] caster.
The last step is to eliminate the spaces in between the letters. We use the -replace function with the parameter “\s\b”. The implied second parameter is “”. This replaces every character that matches that regular expression with nothing. To get a better idea of what this matches, let’s do this with just the first tag “\s”:
Every space is matched including all 3 spaces between the words. When we add in the “\b”, 1 of those spaces is selected:
Now we have
Unfortunately, there are two spaces between the first and last name. I couldn’t figure out a nice regular expressions way to eliminate that extra space. If the -replace function allowed a capture group, I could have used “\w(\s{1,2})” which would have matched all spaces of length 1 or 2 after a word character. This would have left the third space alone.

To adapt this to your own string, look up the ASCII code character by character, subtract 32, and put it into one big string. Then change the 12 in the 0..12 part to however many characters your string is. Or you can run this function:
It will give you the line of code and its output.